Implement no code predicitve modelling with Azure ML studio: step by step

Today we are gonna talk about a very interesting and cool feature of Azure ML studio, that can help you to consume bulk data, to predict complex outcomes, with/without writing any code. Don't believe it? Yeah, this could be done by setting up your Azure ML pipelines, and then implementing proper components to it, that can fiddle with the data, with cleansing, selecting necessary algorthims and training and evaluating the model with outcome scores (that indicates the correctness of your model structure). This article is a step by step process that can guide you to implement the same.
But before I begin, let me refresh you with some basic concepts:
What is a Decision Tree algorthim in Machine Learning?
A decision tree is a supervised learning algorithm that is used for classification and regression modeling. Regression is a method used for predictive modeling, so these trees are used to either classify data or predict what will come next.
Below is an example to evaluate how someone is prone to having a hear attack:



Select your suitable resource group, give a proper name and a region. All else, you can leave as it is, as they come pre-populated.

Click on Launch Studio to continue.


Give a proper name to the instance. Select Virtual machine type as 'CPU':

Although you should need to choose between the option, depending on a lot of parameters. The CPU handles all the tasks required for all software on the server to run correctly. A GPU, on the other hand, supports the CPU to perform concurrent calculations. A GPU can complete simple and repetitive tasks much faster because it can break the task down into smaller components and finish them in parallel.


Addtionally you can go to Applications Tab >> provide Application script. In the environment tab >> Add an environment.

Step 3: create a data asset

Click on Next. Select Source as 'Web files':


This will validate the data within few moments and will come to the next screen:

The above is a post mortem of the data you have uploaded, with every metadata and necessary column datatype details.
And in the next screen, you could get the scehma details:
Click Next and create the Data asset. It will create the data asset like this:

Step 4: Create a new pipeline:
Go to designer >> create a new pipleline: and come to the Data tab, to select the dataset which you just created:

Click on Component tab >> search: Clear missing data >> drag and drop it in the pane. Connect the end Data Output node to Dataset node.

In the above screen shot, I have selected another intermediate step called 'Execute Python script', so as to get rid of null values. But As promised, I won't include any code in this blog, hence I am avoiding that 😅 Double click on the node and you can select all the columns you need to clean up, replace with any value:

And you can give here whichever column you want to manipulate the data with.
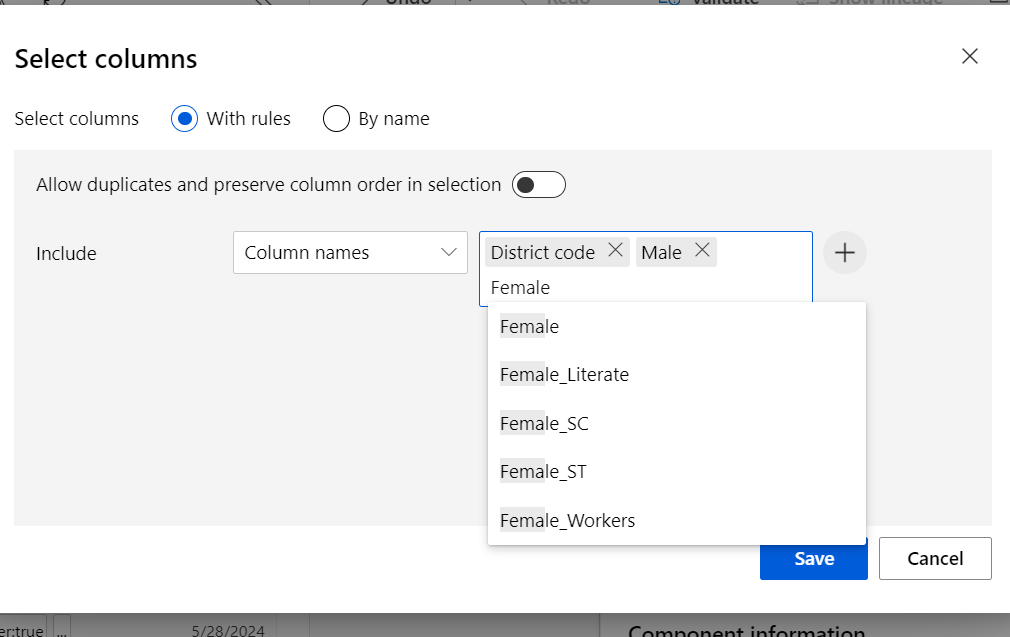
Next, search 'select columns in dataset':

Double click on the node >> select all the fields which youn need by typeing the names:
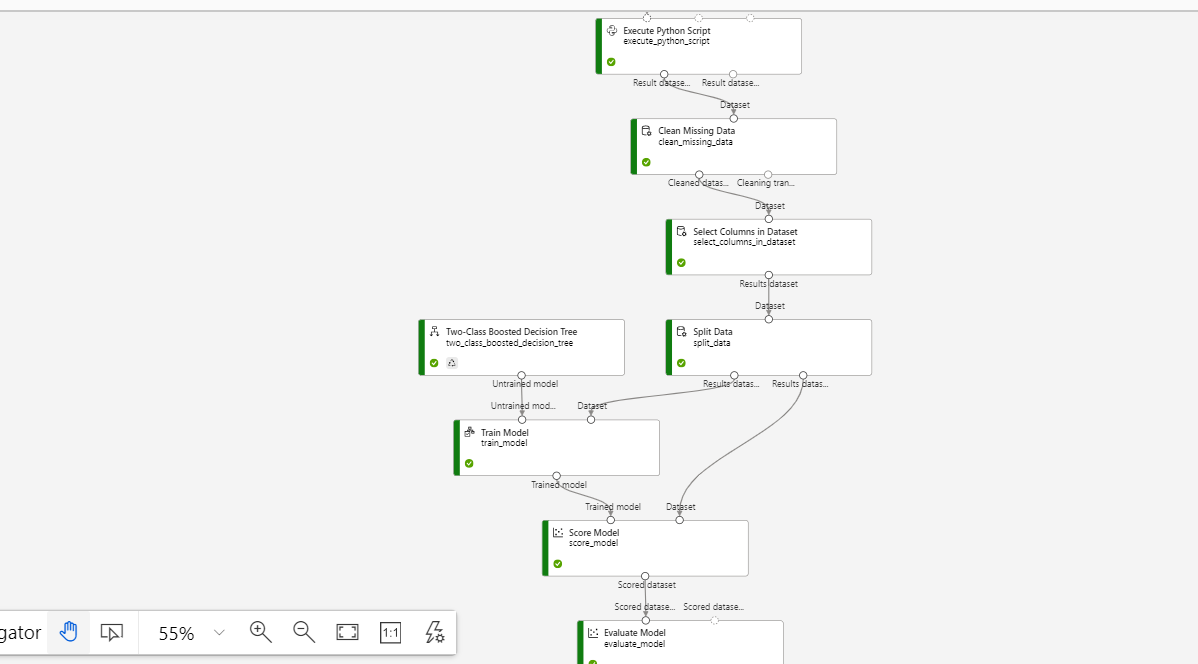
Select 'Two class boosted decision tree', train model, split data, score model and evaluate model. Join them like this one:

Just see how the nodes are connected. Double click on Split data>> select 0.7 as fraction of the data to be trained. In the Train model >> give the label column as 'Population' (implying this is what our model will predict):
Also see, how you are making the model be trained based on the 2-class boosted decision tree algo, and how the score is getting evaluated to the evaluation node.
Done!!!
Click on the 'Auto save' toggle, to make your design be saved, as you keep creating.


In the runtime settings, select the compute instance which you created:

Click Review + submit >> it will initalize the job in a while.
And whew!!! You can go to jobs >> select the job which you created and can see how it's performing, error if any and the outcome:
Post this, if you are not happy with outcome, you can fine tune the result by changing the model or by changing the training data and a lot of other config activities. You can also add to compare to compare between different runs of the program.
Concluding the discussion, here -- would come back with more such awesome features of Azure ML, soon, on another blog. Much love and Namaste💓💓💓



Comments
Post a Comment